News
Take a peek at the latest in computer vision from CVPR 2022: Part One

Machine Learning Resident Tina Behrouzi shares her thoughts on what she saw at this year's CVPR 2022 conference
Tina Behrouzi is a Machine Learning Resident with Amii’s Advanced Tech team. Much of her work focuses on computer vision — specifically deep generative models for vision tasks. In this piece, the first in a series of three posts, she shares some of the advancements she is most excited about from this year’s Conference on Computer Vision and Pattern Recognition (CVPR) in New Orleans.
This summer, at this year’s CVPR 2022 conference, I was surprised by how much exciting new work was on display involving continual learning and vision transformers.
In this series, I’ll be looking at some of those advancements. But first, this post will give a little background on what vision transformers are, the rapid improvement we’ve seen in the technology and how they might influence the future of computer vision in real-world AI applications.
A new way to look at computer vision
It has been just two years since the first Vision Transformer (ViT) network was introduced by Google Research, taking some of the lessons learned from transformers in Natural Language Processing and applying them to images. (You can check this article from AI Summer to learn more about how the ViT works).
Right from the beginning, ViTs offered some major advantages over other methods of using artificial intelligence to analyze and classify images. They can achieve much higher accuracy than methods like Convolutional Neural Networks. ViT models are quickly becoming very popular in almost all vision areas, especially in applications such as multi-modal vision tasks (involving both text and image) and video processing. ViT impressive performance has been seen in models such as DALLE2 and Clip.
However, despite its benefits, ViT still suffers from high computational costs, especially for high-resolution and video inputs. However, in those two short years, we’ve already seen massive strides in improving on ViT — including Multiscale Vision Transformers.
Multiscale Vision Transformers (MViT)
Jitendra Malik is the Arthur J. Chick Professor of Electrical Engineering and Computer Sciences at the University of California, Berkeley. He’s also one of the seminal figures in computer vision. The affection that Malik expressed for his work on Multiscale Vision Transformers during CVPR 2022 immediately made me want to examine it further.
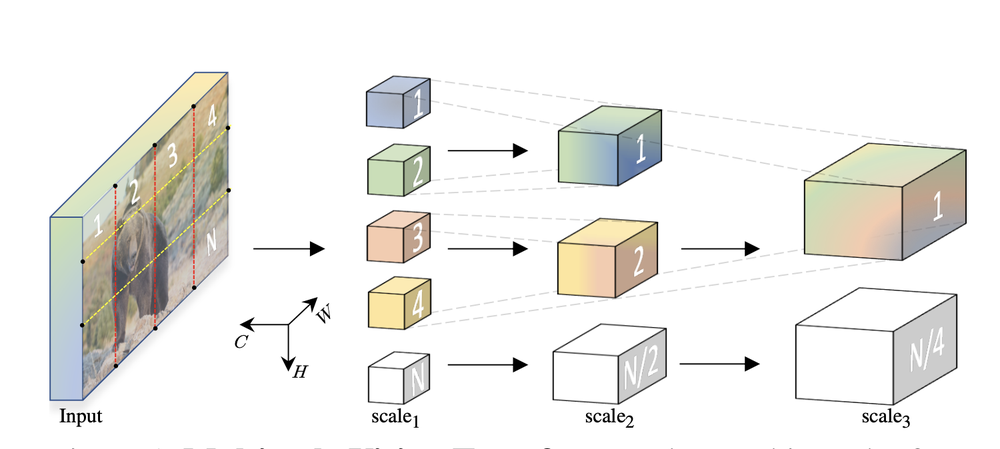
MViT structure: channel size increase and resolution decrease at each step. (Source: Multiscale Vision Transformers, Facebook AI Research)
The first MViT version was published at the 2021 International Conference on Computer Vision. Transformers and self-attention were initially designed for use in Natural Language Processing (NLP) and helped lead to a massive leap forward in improving how artificial intelligence can use language. Therefore, most of the works on ViTs have been on improving frame and patch embedding or training procedures to achieve the same successes that have been seen in NLP.
What I really liked about the MViT work is how they have used the lessons we’ve learned from the dominance of deep Convolutional Neural Networks methods for computer vision up until this point, and using them to inform the way vision transformers are structured. MViT applies the multiscale feature hierarchies, which structure the image into a number of channels, starting with visually dense but simple features and then building up to analyzing more complex features. As shown in the above image, MViT takes the input patches with low-dimensional high-resolution visual features and transfers them to a high-dimensional low-spatial space.
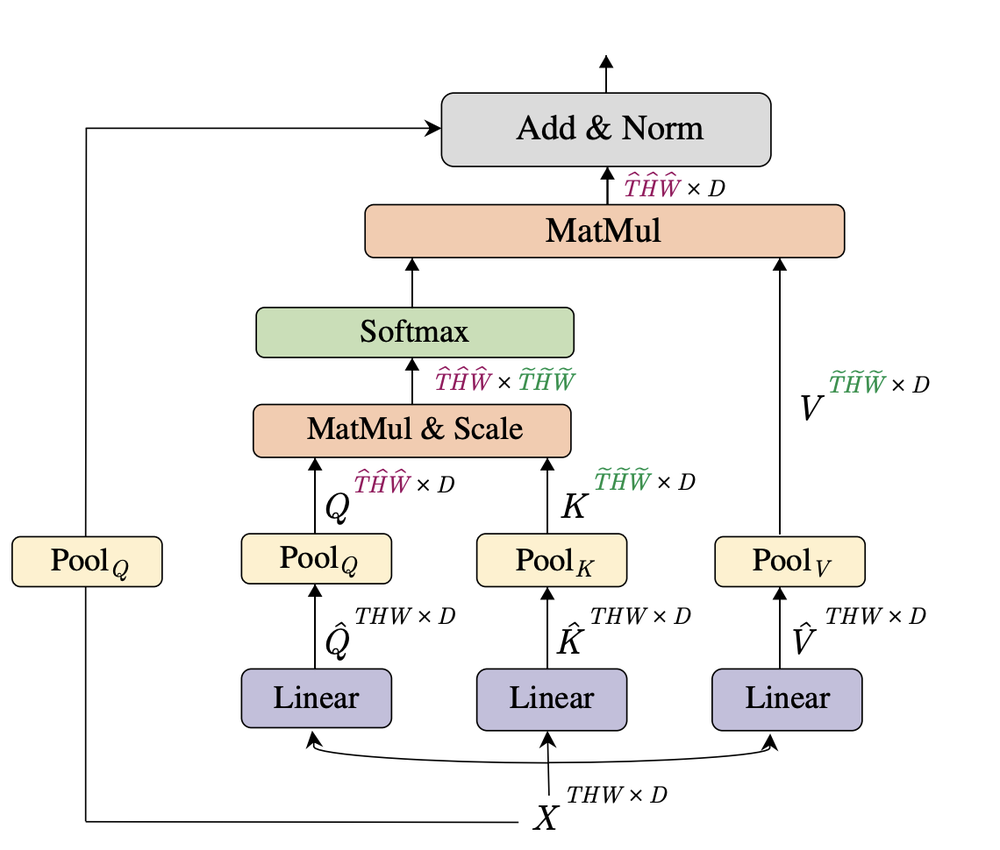
MViT transformer layout (Source: Multiscale Vision Transformers, Facebook AI Research)
The core novelty of MViT lies in the pooling attention mechanism applied to each attention layer’s key, value, and query values. This pooling technique reduces the computation cost of self-attention considerably. As a result, MViT requires considerably less memory and computational resources than other vision transformers: 60% less floating operation per second and 11% higher accuracy compared to ViT-B.
These advances mean that Multiscale Vision Transformers could allow machines to perform better when analyzing images and videos out in the real world — not only with higher accuracy but faster and with less training required compared to previous ViT models. That could help advance technologies like robotics and autonomous vehicles to interact visually with the world.
In the next post, I will look at some further advancements in MViTs, introducing two new models developed by the same group involved with the work above.
Amii's Advanced Tech team helps companies use artificial intelligence to solve some of their toughest challenges. Learn how they can help you unlock the potential of the latest machine learning advances.
Latest News Articles

Apr 8th 2024
News
Cracking the Conference Code
Amii Fellows share tips on how to make the most of your conference experience.

Mar 26th 2024
News
How Chat GPT Ruined Alona’s Christmas | Approximately Correct Podcast
In this month's episode, Alona talks about how ChatGPT changed the public’s perception of what AI language models can do, instantly making most previous benchmarks seem out of date, and the excitement and intensity of working in a fast-moving field like AI.

Mar 18th 2024
News
Google Canada announces new research grants to bolster Canada’s AI ecosystem
Google.org announces new research grants to support critical AI research in Canada focused on areas such as sustainability and the responsible development of AI. The grant will provide a total of $2.7 million in grant funding to Amii, the Canadian Institute for Advanced Research (CIFAR) and the International Center of Expertise of Montreal on AI (CEIMIA).
