News
The Success of DQN Explained by “Shallow” Reinforcement Learning
At the time of writing this post, guest author Marlos C. Machado was a 4th year Ph.D. student at the University of Alberta’s Department of Computing Science, supervised by Amii’s Michael Bowling.
Marlos’ research interests laid broadly in artificial intelligence with a particular focus on machine learning and reinforcement learning. Marlos was also a member of the Reinforcement Learning & Artificial Intelligence research group, led by Amii’s Richard S. Sutton.
In 2013, Amii researchers proposed the Arcade Learning Environment (ALE), a framework that poses the problem of general competency in AI. The ALE allows researchers and hobbyists to evaluate artificial intelligence (AI) agents in a variety of Atari games, encouraging agents to succeed without game-specific information. While this may not seem like a difficult feat, up to now, intelligent agents have excelled at performing a single task at a time, such as checkers, chess and backgammon – all incredible achievements!
The ALE, instead, asks the AI to perform well at many different tasks: repelling aliens, catching fish and racing cars, among others. Around 2011, Amii’s Michael Bowling began advocating in the AI research community for an Atari-based testbed and challenge problem. The community has since recognized the importance of arcade environments, shown by the release of other, similar platforms such as the GVG-AI, the OpenAI Gym & Universe, as well as the Retro Learning Environment.

1. Atari 2600 games: Space Invaders, Bowling, Fishing Derby and Enduro
The ALE owes some of its success to a Google DeepMind algorithm called Deep Q-Networks (DQN), which recently drew world-wide attention to the learning environment and to reinforcement learning (RL) in general. DQN was the first algorithm to achieve human-level control in the ALE.
In this post, adapted from our paper, “State of the Art Control of Atari Games Using Shallow Reinforcement Learning,” published earlier this year, we examine the principles underlying DQN’s impressive performance by introducing a fixed linear representation that achieves DQN-level performance in the ALE.
The steps we took while developing this representation illuminate the importance of biases being encoded in neural networks’ architectures, which improved our understanding of deep reinforcement learning methods. Our representation also frees agents from necessarily having to learn representations every time an AI is evaluated in the ALE. Researchers can now use a good fixed representation while exploring other questions, which allows for better evaluation of the impact of their algorithms because the interaction with representation learning solutions can be put aside.
Impact of Deep Q-Networks
In reinforcement learning, agents must estimate how “good” a situation is based on current observations. Traditionally, we humans have had to define in advance how an agent processes the input stream based on the features we think are informative. These features can include anything from the position and velocity of an autonomous vehicle to the pixel values the agent sees in the ALE.
Before DQN, pixel values were frequently used to train AI in the ALE. Agents learned crude bits of knowledge like “when a yellow pixel appears on the bottom of the screen, going right is good.” While useful, knowledge represented in this way cannot encode certain pieces of information such as in-game objects.
Because the goal of the ALE is to avoid extracting information particular to a single game, researchers faced the challenge of determining how an AI can succeed in multiple games without providing it game-specific information. To meet this challenge, the agent should not only learn how to act but also learn useful representations of the world.
DQN was one of the first RL algorithms capable of doing so with deep neural networks.
For our discussion, the important aspect of DQN is that its performance is due to the neural network’s estimation of how “good” each screen is, in other words how likely it is that a particular screen will result in a favourable outcome.
Importantly, the neural network has several convolutional layers with the ability to learn powerful internal representations. The layers are built around simple architectural biases such as position/translation invariance and the size of the filters used. We asked ourselves how much of DQN’s performance results from the internal representations learned and how much from the algorithm’s network architecture. We implemented, in a fixed linear representation, the biases encoded in DQN’s architecture and analyzed the gap between our bias-encoded performance and DQN’s performance.
To our surprise, our fixed linear representation performed nearly as well as DQN!
Basic & Blob-Prost Features
To create our representation, we first needed to define its building blocks. We used the method mentioned earlier of representing screens as “there is a yellow pixel at the bottom of the screen.”
As Figure 2 (inspired by the original article on the ALE) indicates, screens were previously defined in terms of the existence of colours in specific patches of the image. Researchers would divide the image in 14×16 patches and, for each patch, encode the colours available in that tile.

2. Left: Screenshot of the game Space Invaders; Centre: Tiling used in all games; Right: Representation of Basic Features
In this example, two colours are present in the tile in the top left corner of the screen: black and green. Thus, the agent sees the whole tile as black and green with the “amount” of each colour being unimportant. This representation, called Basic, was introduced in the original paper on the ALE. However, Basic features don’t encode the relation between tiles, that is, “a green pixel is above a yellow pixel.” BASS features, which are not discussed in this post, can be used as a fix but with less than satisfactory results.
When DQN was proposed, it outperformed the state-of-the-art in the vast majority of games. But the question still remained: why?
One of our first insights was that convolutional networks apply the same filter in all different patches of the image, meaning observations aren’t necessarily encoded for a specific patch. In other words, instead of knowing “there is a green pixel in tile 6 and an orange pixel in tile 8,” the network knows “there is a green pixel one tile away from an orange pixel somewhere on the screen.”
This knowledge is useful as we no longer need to observe events at specific locations and can generalize them at the moment they occur. That is, the agent doesn’t need to be hit by an alien projectile in every possible pixel space to learn it’s bad. The AI quickly learns “a pixel above the green pixel (the player’s ship) is bad”, no matter the screen position. We modified Basic features to also encode such information, calling the new representation B-PROS.
3. Representation of B-PROS features
B-PROS is limited in that it doesn’t encode objects movement. If there is a projectile on the screen, is it moving upwards from the agent’s ship or downwards from an alien’s?
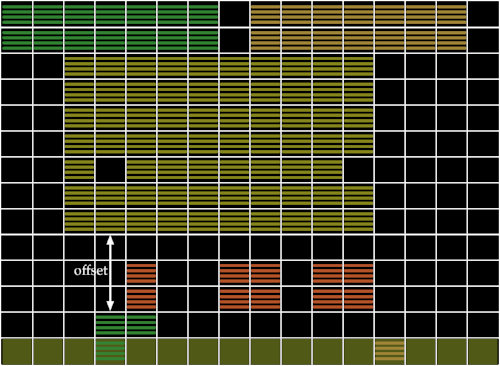
We can easily answer the question by using two consecutive screens to infer an object’s direction, which is what DQN does. Instead of only using offsets from the same screen, we also looked at the offsets between different screens, encoding things like: “there was a yellow pixel two blocks above where the green pixel is now.” We call this representation B-PROST.
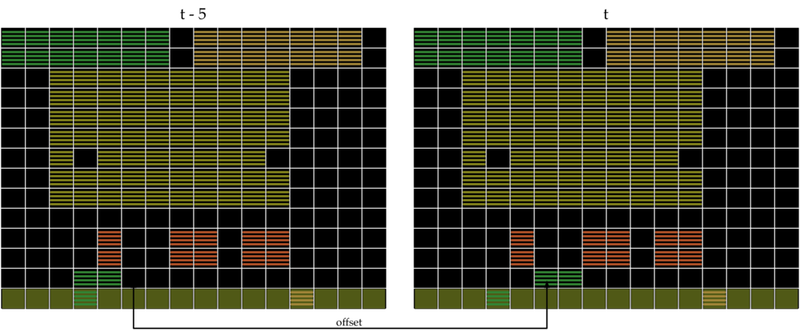
4. Representation of B-PROST features
Finally, as is the case with DQN, we needed a way to identify objects. The filter sizes in the convolutional network had the typical size of objects in Atari games built into the system, so we made a simple change to our algorithm: instead of dividing the screen into tiles, we divided it into objects to examine the offsets between objects. But how to find the objects?
We did the simplest thing possible: call all segments with the same coloured pixels an object. If one colour was surrounding another, up to a certain threshold, we assumed the whole object had the surrounding colour and ignored the colour inside. By taking the offsets in space and time of these objects, we obtained a new feature set called Blob-PROST. Figure 5 is a simplification of what we ended up with.

5. Representation of objects identified for the Blob-PROST feature set
So how good are Blob-PROST features? Well, they score better than DQN in 21 out of 49 games (43 per cent of the games) with the score of three of the remaining games having no statistically significant difference from that of DQN. Even when an algorithm is compared against itself, we would expect it to win 50 per cent of the time, making our 43 per cent a comparable result.
Conclusion
We started by asking how much of DQN’s original performance resulted from the representations it learns versus the biases already encoded in the neural network: position/translation invariance, movement information and object detection. To our surprise, the biases explain a big part of DQN’s performance. By simply encoding the biases without learning any representation, we were able to achieve similar performance to DQN.
The ability to learn representations is essential for intelligent agents: fixed representations, while useful, are an intermediate step on the path to artificial general intelligence. Although DQN’s performance may be explained by the convolutional network’s biases, the algorithm is a major milestone, and subsequent work has shown the importance of the principles introduced by the research team. The state-of-the-art is now derived from DQN, achieving even higher scores in Atari games and suggesting that better representations are now being learned.
For a more detailed discussion of each of the evaluated biases, as well as of DQN’s performance as compared to Blob-PROST, read our paper: “State of the Art Control of Atari Games Using Shallow Reinforcement Learning.”
Latest News Articles

Apr 8th 2024
News
Cracking the Conference Code
Amii Fellows share tips on how to make the most of your conference experience.

Mar 26th 2024
News
How Chat GPT Ruined Alona’s Christmas | Approximately Correct Podcast
In this month's episode, Alona talks about how ChatGPT changed the public’s perception of what AI language models can do, instantly making most previous benchmarks seem out of date, and the excitement and intensity of working in a fast-moving field like AI.

Mar 18th 2024
News
Google Canada announces new research grants to bolster Canada’s AI ecosystem
Google.org announces new research grants to support critical AI research in Canada focused on areas such as sustainability and the responsible development of AI. The grant will provide a total of $2.7 million in grant funding to Amii, the Canadian Institute for Advanced Research (CIFAR) and the International Center of Expertise of Montreal on AI (CEIMIA).
