News
ML Process Lifecycle – Part 2: An In-Depth Look
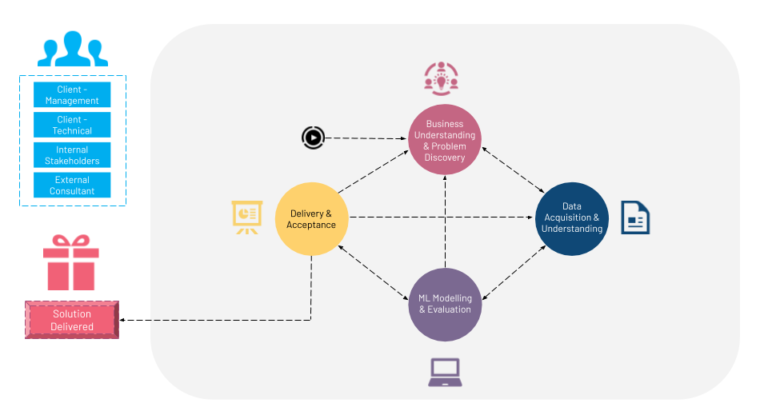
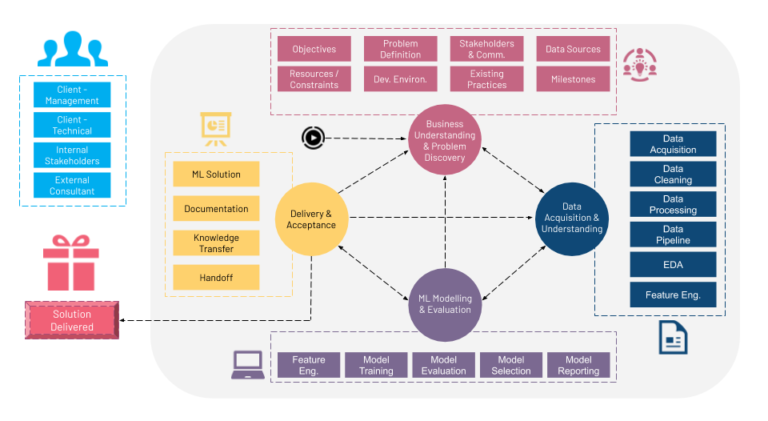
There are four stages in the MLPL:
- Business Understanding and Problem Discovery: This stage identifies a business problem and a corresponding ML problem. For example, if the business problem is to get existing customers to consume more streaming content, a corresponding ML solution could be to implement an algorithm which recommends content they should consume based on their viewing history.
- Data Acquisition and Understanding: This stage explores the available data and identifies the possibilities and restrictions for its use in ML. This would involve an in-depth analysis of the data and its potential.
- ML Modelling and Evaluation: This stage is where the ML algorithms come in. Many organizations start at this stage, assuming it’s the only part of the process that needs to be done to arrive at a solution. However, the first two stages are critical to determining what ML algorithm(s) and configurations to use.
- Delivery and Acceptance: This stage is where we validate if the ML problem is addressing the initial business problem. An ideal project should arrive at this stage only once, but given how quickly a project evolves for various reasons, there is a possibility that this stage may have to be revisited. Good communication among all the stakeholders and clarity in the problem definition will minimize the amount of times this stage will need to be visited.
There are several modules that fall under each of the four stages in the framework.
Business Understanding and Problem Discovery
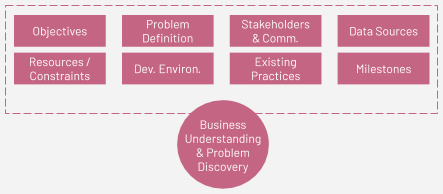
Few key aspects to be taken care of during this stage are:
- Objectives: Identify business objectives that ML techniques can address.
- Problem Definition: Discover the ML problem that would help solve the business problem. Sometimes, there is one exact problem to address one ML problem, and sometimes multiple ML problems together address the business problem.
- Data Sources: Identify existing data sources. In the real world, the data typically comes from different sources and has been combined from these sources. Identifying the data sources will help in narrowing down the data that can be useful. Data sources can be proprietary in-house data, publicly available data, or data that can be bought from third parties.
- Current Practices: Identify what business process or practices are in place that are addressing the business problem in the current setting, if any. The business problem could be completely new or an existing one.
- Development Environment: Define development and collaborative environment (code/data repos, programming languages, etc.).
- Communication: Agree on methods of communication and the frequency of communication.
- Milestones: Define milestones, timelines and deliverables. Sometimes it’s not feasible to arrive at definite milestones, given this is an exploration task. But thinking in that direction will help to add structure.
- Resources: Identify the resources that will be required. The resources can be time, money, employees (e.g. data engineers, analysts, scientists) or computational resources.
- Stakeholders: Identify internal/external stakeholders and their roles. There are usually multiple stakeholders who should be a part of this process continuously. For example, the management team that decided that an ML approach should be tried, a technical team that is actively exploring the solution, teams that would own the different stages of exploration, and third parties associated with the development and deployment of the final solution. All the teams involved in each of the stages of MLPL should be on the same page.
- Constraints: Identify the constraints that are acceptable for the problem. Do we need ML solutions that are interpretable? Is there any part of data that should be removed due to privacy concerns?
By the end of this stage, we would have identified and defined our goals to help us understand the problem better and dive deeper into subsequent stages of MLPL. Worksheets and other tools can be helpful at this stage.
Data Acquisition and Understanding
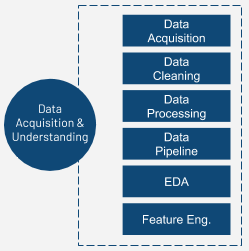
- Acquisition: Acquiring the data is an important task. After the data sources have been identified (in the Business Understanding and Problem Discovery stage), the data sources must be combined into one data source. In some cases, aligning and combining the data sources may require in-depth domain knowledge and expertise.
- Pre-Processing: Data that has been acquired may not be in a form that is readable by tools and libraries used to create machine learning models. There are usually two steps to it. The first one is to translate the data to a form that is related to the ML problem domain. For example, for text processing, if your original data is in a scanned image format, the first step will be to convert those images of text documents into text that can be used by text algorithms. The second step will be to convert the data to either support the specific algorithms (for example: change categorical variables to numerical) or other transformation techniques (for example: standardization, scaling) that will help in improving the results.
- Cleaning: In the real world, data is usually corrupt due to various reasons. Inaccurate readings from sensors, inconsistencies across readings and invalid data are some of the data issues that can be found. A thorough analysis on how to fix these values with the help of a domain and data expert should be carried out.
- Pipeline: A pipeline is a sequence of tasks that can be used to automate repeated tasks. The tasks involved could be extracting data from different sources to a single place, pre-processing data into a form that can be stored and retrieved efficiently and the data can be loaded into a necessary format that can be used by the machine learning algorithms.
- Exploratory Data Analysis: Engage in exploratory data analysis to gain understanding about the data. Understanding the data is very important and could lead to better design and selection of ML process. Also, it gives an in-depth understanding of what could be useful information for further steps.
- Feature Engineering: Feature engineering is a continuous process and would occur in various stages of an ML process. In the Data Acquisition and Understanding phase, feature engineering might be to identify the features that are irrelevant and do not add any information. For example, in high dimensional data, feature engineering may look to remove features whose variance is close to 0.
- Data Split: The data should be split in such a way that there is a portion of data called ‘training data’. Training data is used for training the QuAM and there is a separate portion of data called ‘test data’ to evaluate how good the QuAM is.
ML Modelling & Evaluation
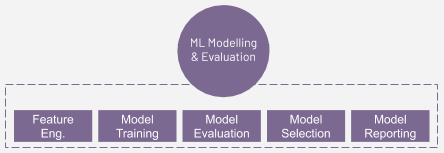
- Algorithm Selection: Algorithm Selection is a process of narrowing down a suite of algorithms that would suit the problem and data. With many algorithms across various domains in ML, narrowing down helps us to focus on certain selected algorithms and working with them to arrive at a solution.
- Feature engineering: This part of feature engineering focuses on preparing the dataset to be compatible with the ML algorithm. Data transformation, dimensionality reduction, handling of outliers, handling of categorical variables are some examples of feature engineering techniques.
- QuAM/Model Training: Once an algorithm has been selected and data is prepared for the algorithm, we need to build the Question and Answer Machine (QuAM) — a combination of an algorithm and data. In the ML world, a QuAM is also referred to as a model. QuAM training includes using the training data to learn a QuAM that can generalize well.
- Evaluation: Identifying the evaluation criteria is an important task. If your task is classification and the success of a model is defined by the number of currently identified instances, then you can use accuracy as your evaluation metric. If there is a cost associated with identifying false positive or false negatives, then other measures such as precision and recall can be used.
- Refinement: Refine the model by identifying the best parameters for each of the algorithms on which you have trained the QuAM. This step is called hyperparameter tuning and is used to find the optimal parameters for a model.
Delivery and Acceptance
This is the stage where we confirm if the ML problem is addressing the business problem. Having a conversation with the employer or client is vital to understanding if the business problem is addressed.
- ML Solution: From the delivery perspective, an ML solution is to be delivered to the client. The solution could be in one or all three of the forms below:
- Prototype: Source code of the prototype is provided along with readme and dependency files on how to use the prototype. The prototype need not necessarily be a production-level code, but should be clean enough with comments, and relatively stable so that the engineering teams can use it to build a product.
- Documentation: Good documentation always accompanies a prototype. Some of the technical details should be listed and explained.
- Project Report: This is a complete list of methodologies used and decisions taken along the lifetime of the project, as well as the reason(s) behind those decisions. This gives a high-level idea of what was achieved in the project.
- Knowledge Transfer: Identify in-house training required for understanding ML solution and present it to the client. This is the appropriate time to clarify questions regarding the ML solution, and acts as a feedback checkpoint prior to incorporating the ML solution into full operation.
- Handoff: Turn over all materials to client so that they can execute it.
Total MLPL Framework
Viewed together, the entire framework looks like this:
In the third and final part of the MLPL Series, we take a look at lifecycle switches and what you can realistically expect on your journey to an ML solution.
Amii’s MLPL Framework leverages already-existing knowledge from the teams at organizations like Microsoft, Uber, Google, Databricks and Facebook. The MLPL has been adapted by Amii teams to be a technology-independent framework that is abstract enough to be flexible across problem types and concrete enough for implementation. To fit our clients’ needs, we’ve also decoupled the deployment and exploration phases, provided process modules within each stage and defined key artifacts that result from each stage. The MLPL also ensures we’re able to capture any learnings that come about throughout the overall process but that aren’t used in the final model.
If you want to learn more about this and other interesting ML topics, we highly recommend Amii’s recently launched online course Machine Learning: Algorithms in the Real World Specialization, taught by our Managing Director of Applied Science, Anna Koop. Visit the Training page to learn about all of our educational offerings.
Latest News Articles

Apr 8th 2024
News
Cracking the Conference Code
Amii Fellows share tips on how to make the most of your conference experience.

Mar 26th 2024
News
How Chat GPT Ruined Alona’s Christmas | Approximately Correct Podcast
In this month's episode, Alona talks about how ChatGPT changed the public’s perception of what AI language models can do, instantly making most previous benchmarks seem out of date, and the excitement and intensity of working in a fast-moving field like AI.

Mar 18th 2024
News
Google Canada announces new research grants to bolster Canada’s AI ecosystem
Google.org announces new research grants to support critical AI research in Canada focused on areas such as sustainability and the responsible development of AI. The grant will provide a total of $2.7 million in grant funding to Amii, the Canadian Institute for Advanced Research (CIFAR) and the International Center of Expertise of Montreal on AI (CEIMIA).
