News
Take a peek at the latest in computer vision from CVPR 2022: Part Two

Machine Learning Resident Tina Behrouzi shares her thoughts on what she saw at this year's CVPR 2022 conference
Tina Behrouzi is a Machine Learning Resident with Amii’s Advanced Technology team. Much of her work focuses on computer vision — specifically deep generative models for vision tasks. In this piece, she shares some of the advancements she is most excited about from this year’s Conference on Computer Vision and Pattern Recognition in New Orleans.
In the first part of the series, she looks the Multiscale Vision Transformer (MViT) and its improvement compared to the previous Vision Transformers (ViT). Here, she will describe two new MViT models introduced at this year’s conference. And part three will look at advances in continual learning and knowledge distillation.
In my last post, I went over some of the exciting progress we’ve seen in the two years in Vision Transformers and how they use some of the lessons learned in Natural Language Processing to create better tools for analyzing images and video. Now, let’s look at a couple of different variations on the Multiscale Vision Transformers (MViT) formula and how they’re geared toward tackling specific issues in the computer vision world.
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection
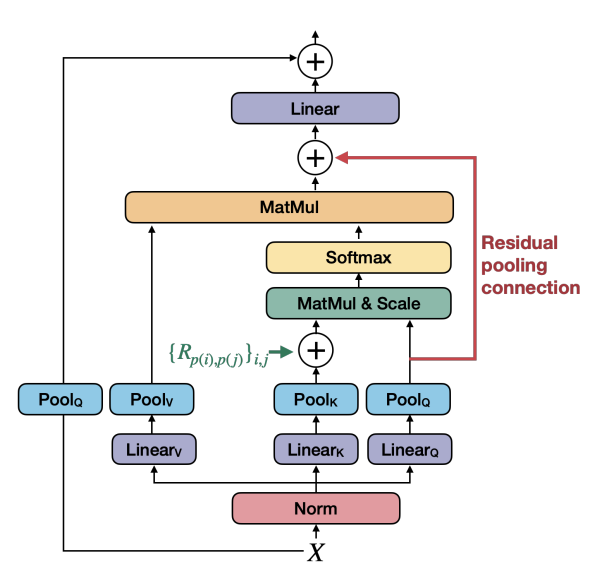
MViTv2: Improved MViT (Fan, 2022
As described by Haoqi Fan, MViTv2 proposes two main technical improvements over the original MViT network.
First, MViTv2 adds shift-invariant decomposed relative positional embedding to the attention unit as shown by the green arrow in the above image. In the MViT model, the connection between patches is determined by their absolute position in the image. So for example, when the transformer looks at a photo and identifies a tree, part of the information it uses is the exact location of the tree in the image. This can cause a problem classifying the tree in later images if it shifts positions.
MViTv2 addresses this issue by adding a shift-invariant embedding tensor, which relies more on the different parts of the tree image and relatively how far they are from each other. That makes it more robust when analyzing images with slight variations in them.
Second, MViTv2 includes a residual pooling connection with the pooled-query tensor to compensate for the larger key and value size.
In my previous post, I mentioned how multiscale vision transformers use a series of pooling attention layers to build an understanding of an image. A pooling layer is a technique for downsampling spatial resolution of the feature map. It simplifies the processes by only sending along the most useful data needed for the next step in analyzing the image. This saves on both time and resources and makes the model less dependent on variations in a pooled region’s feature positions.
MViTv2 holds on to some of that pooled query data, so it can use it on later layers in the process. This allows information to flow between the layers more easily. In general, the residual connection has been shown to be very effective in video and vision tasks with deep neural networks.
While the Multiscale Vision Transformers I mentioned in part one are focused on video, MViTv2 tries to address other vision tasks. The aim is to create and define a unified backbone that can be used for problems that involve classifying images, detecting objects and grabbing visual information from video.
Despite the improvements it offers, MViTv2 does have some limitations. Currently, a lot of research goes into making vision transformers less complex, so they can be used on mobile devices. MViTv2 still needs to be scaled down if it is to work on mobile applications.
Moreover, MViTv2 has only been adapted for specific, limited vision tasks. It would be great to evaluate the performance of MViTv2 on other databases. I’d love to see its structure optimized to be more general and easily adjustable, which would let it be used for different applications without a lot of additional fine-tuning
MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition
MeMVIT extends the MViT for long-term video recognition applications (Wu, 2002). Most current video-based action identification models only analyze short pieces of video (between 2-3 seconds). However, MeMVIT can process videos 30 times longer than state-of-the-art models with a comparably slight increase in computational cost. Additionally, this model reuses the previously contained memory (demonstrated in the image below), which helps further reduce the memory cost. This makes running the transformer more lightweight and less resource intensive.
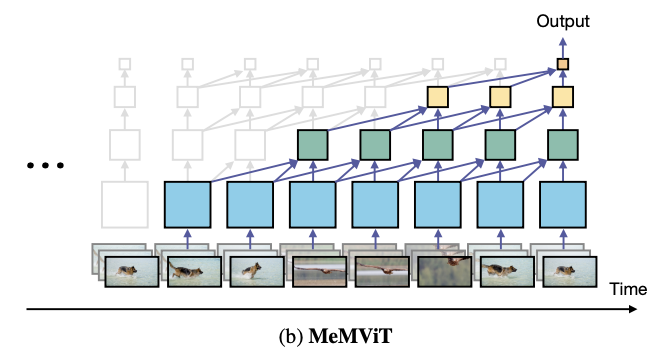
Illustration of how catched feature map gets updated based on new frames (Wu, 2022)
MeMViT employs an online learning technique so that it can adapt with new information without needing to be shut down and retrained. This approach is inspired by how humans' eyes interpret a video by processing frames one by one and then comparing it with previous knowledge. The key and value parameters of the transformer get updated based on the new information.
MViT and its variants consider the structure properties of deep vision networks, which can be valuable for video processing and visual recognition tasks. The variations presented at CVPR 2022 are working towards solving problems like long-term video recognition and dealing with small differences in images. These will be important as we try to tackle more complex computer vision tasks both in research and in real-world applications.
In the final part of my series on CVPR 2022, I’ll move away from vision transformer models and take a look at what the conference offered on two techniques that I think will make a big impact on the future of computer vision research: continual learning and knowledge distillation.
Amii's Advanced Tech team helps companies use artificial intelligence to solve some of their toughest challenges. Learn how they can help you unlock the potential of the latest machine learning advances.
Latest News Articles

Jul 24th 2024
News
Humans Make AI Better with Matt Taylor | Approximately Correct Podcast
How do we get the best results when AI and human beings work together? In this episode of Approximately Correct, we’re looking into Human-In-The-Loop AI with Amii Fellow and Canada CIFAR AI Chair Matt Taylor.

Jul 22nd 2024
News
Amii Monthly News - July 2024
Read our monthly update on Alberta’s growing machine intelligence ecosystem and exciting opportunities to get involved.

Jul 18th 2024
News
Empowering Founders: Amii’s Collaboration with Communitech Aims to Fuel AI Adoption
Amii announces work with Communitech, a Waterloo Region innovation hub, to empower startup founders with the AI tools and resources they need to integrate AI and build in-house capabilities successfully. The collaboration will leverage Amii’s leading AI expertise and resources and be centred around Amii’s Machine Learning Exploration (ML Exploration) program.
