News
Take a peek at the latest in computer vision from CVPR 2022: Part Three

Machine Learning Resident Tina Behrouzi shares her thoughts on what she saw at this year's CVPR 2022 conference
Tina Behrouzi is a Machine Learning Resident with Amii's Advanced Tech team. Much of her work focuses on computer vision — specifically deep generative models for vision tasks. In this piece, she shares some of the advancements she is most excited about from this year's Conference on Computer Vision and Pattern Recognition in New Orleans.
In Parts One and Two of the series, I looked at recent advancements in Multiscale Vision Transformers (MViT) and its variants. Now, I want to focus on two techniques that are having a big impact on the way computer vision models are trained: knowledge distillation and continual learning.
Knowledge distillation: A good teacher is patient and consistent
Many computer vision networks are quite deep and have a slow inference speed making them challenging and costly to deploy in production. Knowledge Distillation (KD) is a technique to train a smaller, faster, and more cost-efficient student model under the supervision of a complex and strong teacher model.
Knowledge Distillation (KD) is popular for model compression. Instead of using a single complex, resource-hungry mode, KD uses a teacher model that is pre-trained on data and then passes its results along to a less complex student model to train on. The student network can potentially need less storage, take less time or work on less powerful hardware than its teacher network would.
As well, the teacher network considers the effects of data augmentation, which can solve the problem of insufficient training info by generating new artificial data points from the ones that already exist. By passing the generated data through the teacher to estimate the probability of output, things like human annotation are not required to label the augmented data.
Finally, in many deep computer vision networks, which are trained end2end, different submodules of the network are designed to handle specific tasks. In a computer vision model designed to swap two faces, for instance, one module might be responsible for determining the major features of the face, while another might handle figuring out the face's position in the image. KD helps provide labels for training those submodule networks.
Function Matching (FunMatch):
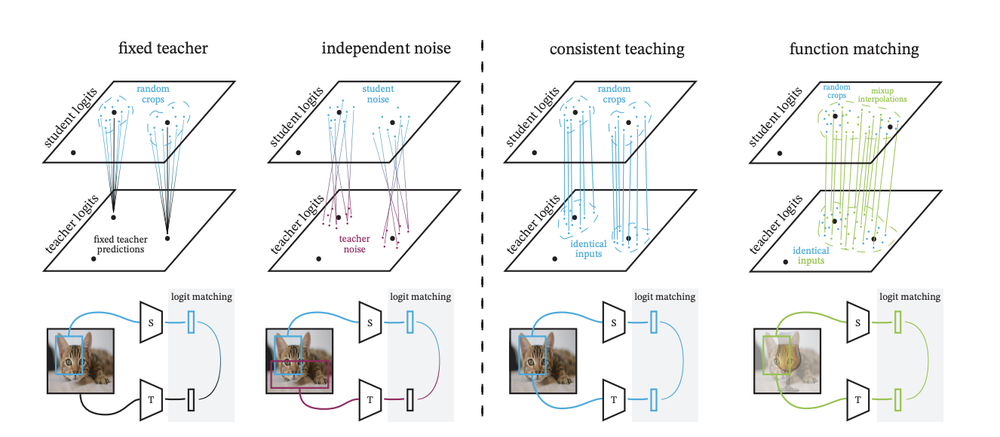
Comparison of FunMatch with other distillation techniques (Beyer, 2022)
In FunMatch, the Google Research team introduces the current best procedure and framework for training a student network. This work tackles the challenge of transferring large-scale models into small models with efficient cost. FunMatch introduces three important steps that should all be applied together in knowledge transfer for the best results. For instance, it emphasizes that an exact input with the same augmentation and cropping must be passed to both teacher and student models.
FunMatch showed the best performance of Resnet50, a popular convolutional neural network, trained on the ImageNet image database with more than a 2% increase in accuracy compared to state-of-the-art models. However, one of the challenges is that this method cannot be applied to precomputed teacher prediction of an image done offline.
CaSSLe: Self-supervised Models are Continual Learners
Continual learning (CL), sometimes called continuous learning, has been gaining a lot of attention in many areas of machine learning. The idea is to continuously train a network based on new data without losing previous information. CL-based models usually tackle that by keeping part of a network intact while optimizing the other sections. A good continual learner captures data properties that keep changing in time. In this year's CVPR, there were many works on CL for vision tasks to improve the long-term applicability of computer vision models.
One of the main challenges of CL in vision is that computer vision networks are usually costly and deep, making expanding all layers' parameters impractical. To keep the computational cost reasonable, researchers only apply the continual learning paradigm to specific layers and just a part of a network. Therefore, they need to find the most effective layer to get expanded.
Almost all of the current successful models that use CL in vision are trained in a supervised approach. That is why the CaSSLe model, which works with self-supervised models, captured my eyes at the conference.
CaSSLe:
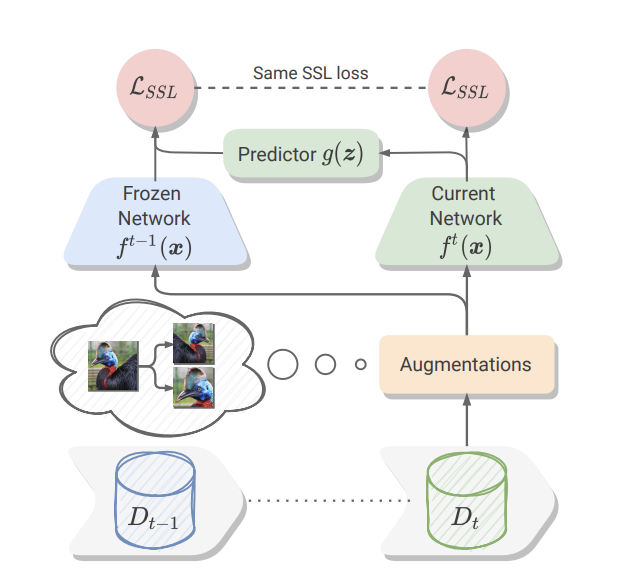
CaSSLe framework overview (Fini, 2022)
CassLe is a framework for continuously training a self-supervised model. This work mentions that the regularization techniques in CL are detrimental in a self-supervised setting. Additionally, the CL method needs to be compatible with current self-supervised models to be effective. Therefore, CaSSLe introduces two approaches to facing these issues:
First, CaSSLe employs a distillation technique for learning new information based on previous predictions. Second, a predictor model is designed and applied to new features that transfer them to a new space. In this way, the new and old features are not compared one by one, which helps the network learn new knowledge.
CaSSLe reduces the size of data required for pre-training a network. Also, CaSSLe is simple and compatible with state-of-the-art self-supervised models. Moreover, the author claims that extra hyperparameter tuning is not required with respect to the original self-supervised method.
However, saving previous encoder weights and adding additional predictor networks make the CaSSLe method computationally expensive — it can increase the memory and time cost of a self-supervised network by 30%.
Knowledge distillation has already gained huge success in computer vision. In this year's CVPR, FunMatch introduced a better and more general framework for KD. Additionally, CassLe presented a new mechanism for continually learning of a self-supervised model structure in this ever-changing world. I believe these two training techniques will be pivotal in building light and adaptive networks in the future of CV.
Amii's Advanced Tech team helps companies use artificial intelligence to solve some of their toughest challenges. Learn how they can help you unlock the potential of the latest machine learning advances.
Latest News Articles

Jul 24th 2024
News
Humans Make AI Better with Matt Taylor | Approximately Correct Podcast
How do we get the best results when AI and human beings work together? In this episode of Approximately Correct, we’re looking into Human-In-The-Loop AI with Amii Fellow and Canada CIFAR AI Chair Matt Taylor.

Jul 22nd 2024
News
Amii Monthly News - July 2024
Read our monthly update on Alberta’s growing machine intelligence ecosystem and exciting opportunities to get involved.

Jul 18th 2024
News
Empowering Founders: Amii’s Collaboration with Communitech Aims to Fuel AI Adoption
Amii announces work with Communitech, a Waterloo Region innovation hub, to empower startup founders with the AI tools and resources they need to integrate AI and build in-house capabilities successfully. The collaboration will leverage Amii’s leading AI expertise and resources and be centred around Amii’s Machine Learning Exploration (ML Exploration) program.
